Intelligent Ticket Routing in ITSM: From Manual Triage to Governed Automation

At enterprise scale, manual ticket routing fails predictably. Tickets bounce between assignment groups before reaching the right team, and every handoff pushes resolution further out. Each reassignment delays an employee who cannot do their job until the ticket is resolved, and those delays compound across every service level agreement (SLA) and satisfaction metric IT operations teams track.
Intelligent ticket routing solves the routing problem, but only when it is deployed inside the governance guardrails that keep AI deployments on track. In this article, we’ll cover how intelligent ticket routing works, why manual routing fails at enterprise scale, and how to implement it to improve resolution speed and accuracy.
How Intelligent Ticket Routing Works
Traditional IT service management (ITSM) routing depends on static IF-THEN rules: if a ticket mentions "VPN (virtual private network)," route it to Network.
That approach worked when IT environments were simpler, but modern infrastructure has outpaced it.
Intelligent ticket routing replaces those rules with a pipeline of machine learning (ML) and natural language processing (NLP). The pipeline reads the incoming ticket, determines what it is, assesses its urgency, and assigns it to the right person. Human dispatchers keep their focus on the exceptions that genuinely require judgment.
ML-based routing also gets better as the model learns from resolved tickets. Rule-based routing does not improve on its own.
AI classification works well when the input is unstructured or ambiguous, such as free-text descriptions, misspelled device names, or urgency signals buried inside user narratives. Deterministic rules work better when a routing decision must produce the same result every time: SLA-tier assignment, compliance category routing, and escalation paths that have to hold up to audit. Running an AI model on a decision rule could have handled ad token spend without improving accuracy, and creates another place where routing can go wrong. The platforms worth evaluating let teams configure each routing step separately, with deterministic rules handling the logic teams already trust and AI classification applied to the steps that need interpretation.
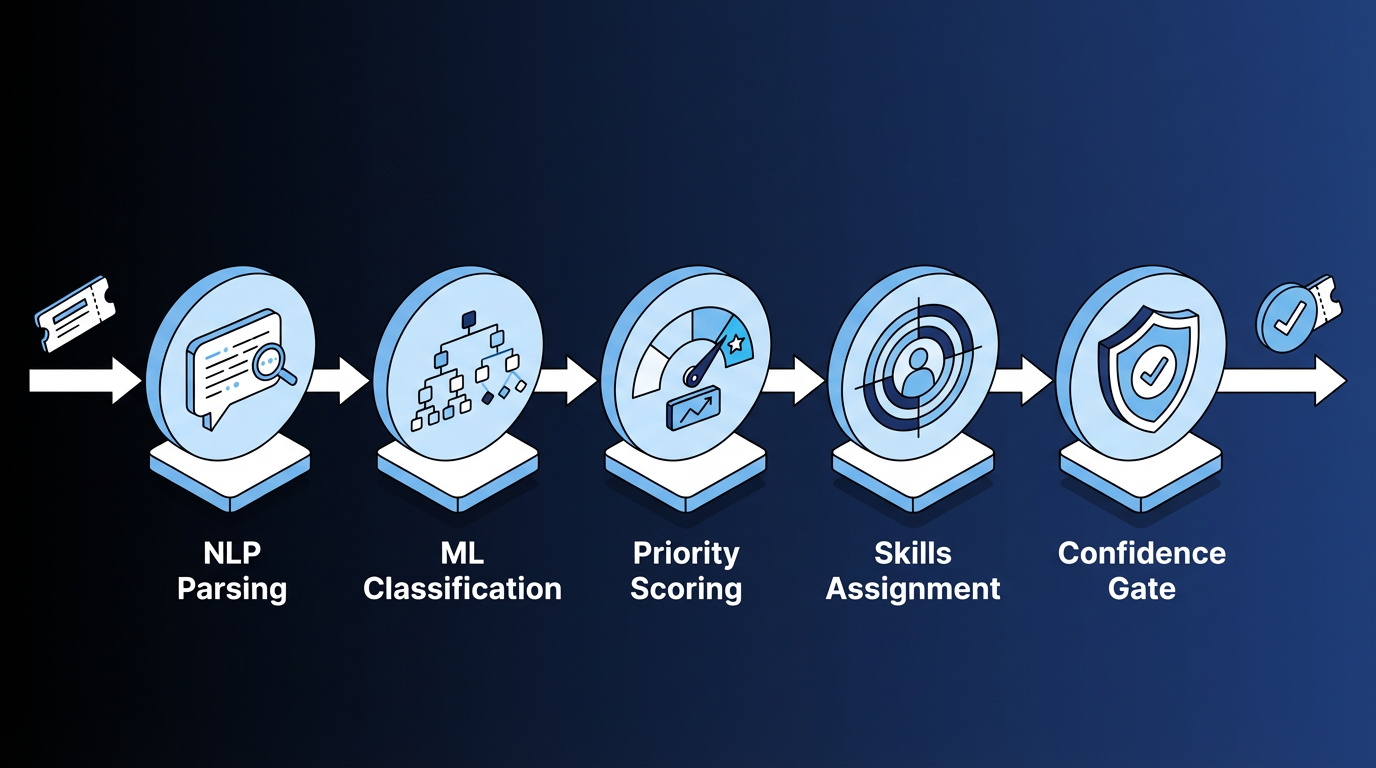
The pipeline usually consists of the following:
- NLP parsing: Extracts structured meaning from the vague, misspelled descriptions users actually type. Device names, error codes, and urgency signals become structured fields that feed the classification model.
- ML classification: Populates category, subcategory, and assignment group fields automatically.
- AI-driven priority scoring: Determines priority based on actual ticket content and business context.
- Skills-based assignment: Routes to the right individual within the right team based on documented expertise, current queue depth, and historical resolution performance.
- Confidence gating: When the model is not confident, the ticket routes to a human triage queue with the top suggestions visible rather than executing autonomously. In production-style research, ensemble ML approaches have placed the correct resolution group within the top three predictions for the majority of tickets evaluated.
Why Manual Routing Breaks Down at Enterprise Scale
Routing failures accumulate, and each misrouted ticket extends the next one's resolution window. Volume growth makes the problem worse: the more tickets a team handles, the more categorization decisions per hour, and the more places where one of those decisions can go wrong.
A 2024 report found that 34% of organizations had seen an increase in ticket volumes driven by new applications, devices, and users. Categorization schemas that worked five years ago now span hundreds of choices across platform and category fields, and every new choice is another place a ticket can be misclassified.
In larger enterprises, many help desk tickets are submitted by employees who cannot perform their jobs until the issue is resolved. Every routing delay extends that lost productivity. Faster resolution also directly feeds into customer satisfaction scores: once a user is frustrated, multi-day resolution times make it much harder to recover the relationship.
SLA performance does not always reflect what users actually experience. A ticket can meet its SLA on paper while the user endures repeated delays due to multiple reassignments, which is why enterprise ITSM frameworks treat tickets routed across multiple assignment groups as a process failure. SLA timers alone do not reflect the real user impact.
How to Implement Intelligent Ticket Routing
Implementation challenges in AI ticket routing projects often center on integration and change management, though technical complexity can also play a role. A phased approach helps reduce deployment risk by validating accuracy before automating decisions.
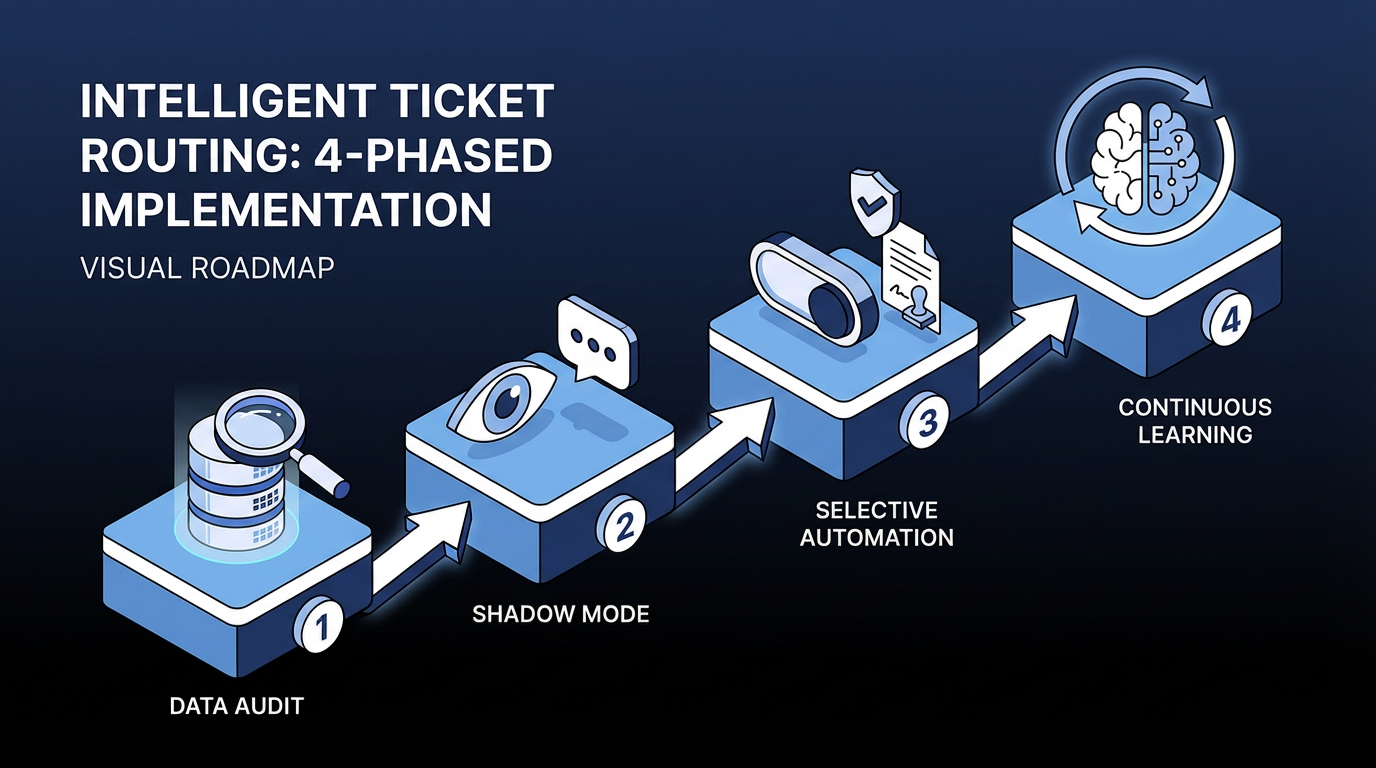
- Phase 1: Data audit and baselining. Audit historical ticket data for labeling consistency before training any model. Reliable accuracy requires a large, consistently labeled dataset; thin or inconsistent labels produce thin, inconsistent routing regardless of the model. Without a baseline of current routing accuracy, misrouting rate, and SLA breach rate, you cannot measure improvement.
- Phase 2: Shadow mode. Deploy AI routing in suggest-only mode. The model recommends assignments, and agents confirm or override each one. Log every override with a reason code. Those reason codes build trust in the model now and feed correction data into the next training cycle.
- Phase 3: Selective automation with human gates. Automate categories once accuracy stays above the defined threshold for four consecutive weeks in shadow mode. Priority-one and priority-two (P1/P2) incidents, security events, and tickets touching regulated systems still require mandatory human approval regardless of model confidence. Without configurable approval thresholds, a misconfigured model can misroute high-priority incidents repeatedly before anyone notices.
- Phase 4: Continuous learning. Define triggers for model review: accuracy drops of more than 5 percentage points; override rates above 20% in any category over a rolling 30-day window; new service introductions; or organizational restructuring. Set retraining cadence based on model performance, data drift, and the specific use case, not on a calendar.
These phases depend on having clear operational control in place. Confidence threshold settings should sit with operations team leads, not behind engineering deployments.
When SLA pressure peaks, teams need to adjust thresholds quickly, without waiting for a code deploy or submitting another IT ticket.
Apply Intelligent Ticket Routing With Governed Workflow Orchestration
Elementum's Workflow Engine brings together business rules, AI-driven decisions, and human review within a single workflow. Agent Gateways let teams stack routing logic in priority order, assigning deterministic rules to steps that require consistent results and AI classification to steps that require interpretation, with configurable confidence thresholds that govern when autonomous execution hands off to human review.
When model confidence falls below the defined threshold, tickets route to a human reviewer with full context instead of proceeding automatically. Teams often begin with a focused use case, such as ticket routing, and expand into additional ITSM workflows as confidence in the system grows.
As workflows mature, the same orchestration approach can extend into other operational areas, including procurement, HR, and finance, without introducing new systems or duplicating logic.
Our Zero Persistence architecture keeps ticket data in its original systems, without training on it, replicating it, or storing it elsewhere. Scoped workflows typically reach production within 30 to 60 days, without requiring a full platform replacement.
Contact us to map intelligent routing into your ITSM workflow and the rest of your AI roadmap.
FAQs About Intelligent Ticket Routing
How Accurate Is AI Ticket Routing Compared to Manual Triage?
AI classification accuracy in ticket routing depends more on the quality of the training data. Models trained on clean, consistently labeled ticket history perform significantly better than those trained on inconsistent data.
In practice, most systems provide several likely assignment options, with the correct group appearing among the top suggestions for most tickets.
Do Enterprises Need to Replace Their Current ITSM Product to Get Intelligent Routing?
Not always. Many enterprises keep their existing ITSM platform and add a governed orchestration layer on top of it, especially when tickets span multiple systems or business units. Others go further and consolidate onto an orchestration platform that can replace a legacy ITSM product outright; Elementum serves as a ServiceNow alternative for teams looking to simplify their stack. The right question is whether your orchestration layer provides sufficient control over routing, governance, and audit trails to justify the cost of the platforms you are already paying for.
How Long Does Implementation Take Before Routing Is Accurate?
System go-live and production-grade routing accuracy are two different milestones. Most teams reach go-live quickly; achieving accurate, trusted routing takes longer because it depends on data auditing, shadow mode, and a validation period before the model is trusted to make autonomous decisions. A large, consistently labeled dataset is the foundation. Teams that skip shadow mode and automate too early tend to see elevated override rates, which erodes trust in the system and stalls broader rollout.
Which ROI Metrics Support an Internal Business Case for Intelligent Routing?
Common evaluation metrics include mean time to resolution, first-contact resolution rate, reassignment rate, cost per ticket, and user satisfaction scores. While vendor-reported ROI figures vary, the most reliable business case starts with your own baseline: measure current misrouting rates, then define a target reduction that directly impacts SLA performance and cost per ticket.
What Happens When the AI Gets a Ticket Wrong?
Well-configured systems rely on confidence thresholds. When no classification meets the threshold, the ticket routes to a human triage queue with suggested assignments visible.
A key consideration is who controls those thresholds. If adjustments require engineering support, teams introduce delays at the exact moment when speed matters most. Operational teams should be able to adjust thresholds directly to maintain control under pressure.
Keep Reading

The Enterprise Guide to Agentic AI for ITSM
How to Build an IT Issue Escalation Process That Scales

How To Set Up an AI-Powered IT Service Desk Workflow

Human-in-the-Loop vs. Human-on-the-Loop: When to Use Each for Enterprise Workflows

Deterministic vs. Probabilistic AI: The Enterprise Guide to Building Workflows That Scale

How to Create IT Issue Remediation Workflows for Enterprise Teams